
睡眠分数的幻觉:手环为什么越准,越可能把你带偏
这篇长文从 orthosomnia 病例切入,拆解消费级睡眠追踪器为什么能较好识别睡着,却常常低估清醒、误导深睡解释,并把反馈变成安慰剂或反安慰剂。读者将获得一套使用睡眠分数的实证框架:看长期趋势,不审判单夜。

手环最擅长的不是告诉你昨晚睡得怎样,而是把一夜的混乱压成一个像成绩单的数。这个数有时有用。它能提醒你连续几天只睡了五小时,也能让医生看到作息漂移。麻烦在于,它看起来太像事实了。
2017 年,Kelly Glazer Baron 等睡眠医学研究者给这种现象起了一个不太好翻译的名字:orthosomnia。词根「ortho」指正确,「somnia」指睡眠。病人不再只追求睡得好,而是追求设备显示自己睡得正确。那篇病例报告里,一名患者把治疗目标说成「每晚至少 8 小时深睡眠」,另一名患者在实验室多导睡眠图显示深睡眠比例正常甚至偏高后,仍追问医生:「那为什么我的 Fitbit 说我睡得很差?」1
这不是一个反技术故事。睡眠追踪器确实比许多健康小玩具更接近可用测量。近年的消费级设备可以记录运动、心率、皮温、呼吸相关信号,某些设备在判定「睡着」这件事上表现不错。Evan Chinoy 等人在睡眠实验室把 7 种消费级设备和多导睡眠图比较,发现所有设备逐 epoch 判定睡眠的敏感性都不低于 0.93。问题藏在另一半:它们识别清醒的特异性只有 0.18 到 0.54,睡眠分期结果也不稳定。2
所以更准确的说法不是「手环胡说」。它们常常在一个狭窄任务上有用,在另一个读者更在意的任务上很弱。手环知道你大概率安静躺了多久,却不一定知道你在床上睁眼焦虑了多久;它能给你「深睡」分钟数,却未必有足够证据把那些分钟数当成临床意义上的 N3 睡眠。
睡眠不是一个能直接称重的东西
多导睡眠图(PSG)被称为睡眠测量的金标准,因为它同时记录脑电、眼动、肌电,以及呼吸、心电、血氧、体位等信号。睡眠技师按美国睡眠医学会规则,把整夜记录切成 30 秒一段,再给每段标上清醒、N1、N2、N3 或 REM。de Zambotti 等人的综述把 PSG 描述为设备验证的主要参照,但也指出 PSG 昂贵、笨重,需要实验室设备和受训人员,不适合长时间居家追踪。3
这就给活动记录仪(actigraphy)留下空间。活动记录仪用腕部加速度推断睡眠和清醒,基本假设很朴素:动得多更可能醒着,不怎么动更可能睡着。它便宜、轻便,能连续戴几天到几周。美国睡眠医学会 2018 年指南建议,在成人和儿童失眠、昼夜节律睡眠-觉醒障碍、疑似睡眠不足综合征等场景中,可以用 FDA 批准的活动记录设备估算睡眠参数;同一指南也明确说,消费级可穿戴设备不在该指南范围内,actigraphy 不能替代有指征时的实验室 PSG。4
这个表里最容易被忽略的是「盲点」一列。睡眠追踪器把一个多通道生理状态压成几个指标:总睡眠时间、入睡潜伏期、睡眠效率、清醒时间、浅睡、深睡、REM。每压缩一次,误差的形状就变一次。总睡眠时间的误差,和深睡分钟数的误差,不是同一种错误。
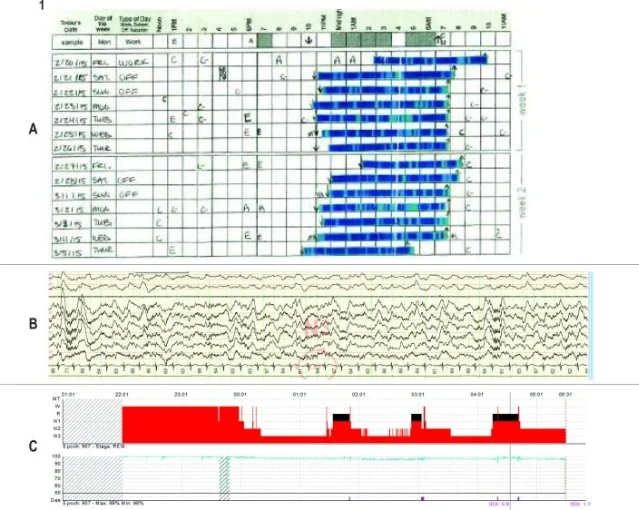
手环的强项,也是它的诱导项
一个二分类器可以靠很高的敏感性显得很好。夜里多数 30 秒片段本来就是睡眠,设备只要倾向于把安静片段判成睡眠,就能在「识别睡着」上拿到漂亮数字。代价是清醒片段会被吞掉。
de Zambotti 等人总结了 actigraphy 的老问题:多数研究显示它识别睡眠的敏感性和总体准确率较高,但识别真实清醒的特异性较差。健康参与者研究中的特异性范围为 26.9% 到 77%,临床样本中约为 32.5% 到 80%;许多研究低于 50%。3 这不是某个品牌的丑闻,而是测量原理带来的结构性偏差:人可以在床上醒着不动。
Chinoy 等人的七设备实验把这个偏差放到更现代的消费级设备上。34 名健康年轻成人在实验室连续三夜接受 PSG,同时使用 4 种腕戴设备和 3 种非腕戴近身设备;其中一晚包含实验性睡眠打断。结果更细:多数设备在睡眠/清醒指标上可与 actigraphy 相当或更好,但 Garmin 两款设备表现较差;所有设备的睡眠敏感性都很高,特异性仍只有低到中等;睡眠阶段估计混合不一,且在睡得差或被打断的夜晚更容易出问题。2
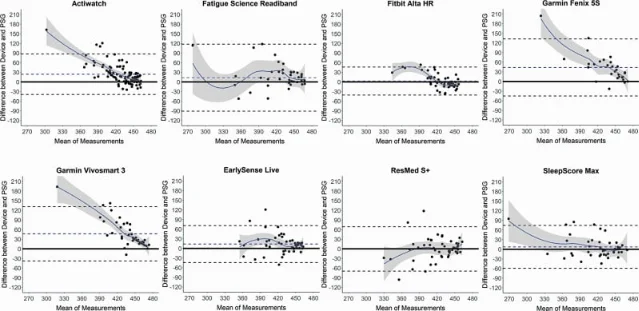
Loading chart…
上图改写自 Chinoy 等人的 WASO(入睡后清醒时间)表。负数表示设备低估了 PSG 记录到的清醒分钟数;Garmin Fenix 5S 和 Vivosmart 3 分别低估约 49.5 分钟和 47.6 分钟。2
这个方向的错误很容易制造心理错觉。一个经常夜醒的人看到设备说「你睡了 7 小时 40 分钟」,会怀疑自己的主观感受。另一个人看到设备说「你深睡太少」,又会怀疑自己的身体。两种怀疑都可能是真的,也都可能被设备放大。
「深睡 43 分钟」比「我睡得差」更像事实
分数的危险不只来自误差,还来自外观。一个整数会把模型输出伪装成客观读数。用户很少看到原始光电容积脉搏波、加速度计噪声、缺失数据、固件版本、训练样本边界、分类阈值。他看到的是 82 分、6 小时 58 分、深睡 43 分钟。
de Zambotti 等人把消费级设备的几个限制说得很直白:它们是面向普通消费者的商业设备,不是为临床或研究设计;多数设备的算法是专有黑箱,原始传感器数据不可得;公司可以在不通知研究者的情况下改变算法;科学验证速度慢于硬件和软件迭代,等某型号有验证证据时,它可能已经停产。3
这解释了为什么横向比较常常靠不住。你今年的手表分数,未必能和去年的同一手表分数比较;同一晚戴两只设备,未必能得到同一个「深睡」;设备给出的「light」「deep」「REM」也不一定等价于 PSG 的 N1、N2、N3、REM。Chinoy 的实验为了比较设备睡眠阶段,不得不把 PSG 的 N1 和 N2 合并为 light,把 N3 当作 deep,因为消费级设备通常只输出「浅」「深」「REM」三类。2
更麻烦的是,金标准本身也不是神谕。Lee 等人 2022 年做了 PSG 人工睡眠分期评分者间一致性的元分析,纳入 11 项研究;总体 Cohen’s κ 为 0.76,属于相当一致,但各阶段差异很大:清醒期 0.70,REM 0.69,N2 和 N3 都是 0.57,N1 只有 0.24。5 换句话说,就连受训技师看着脑电图,也会在 N1 这种过渡状态上分歧很大。
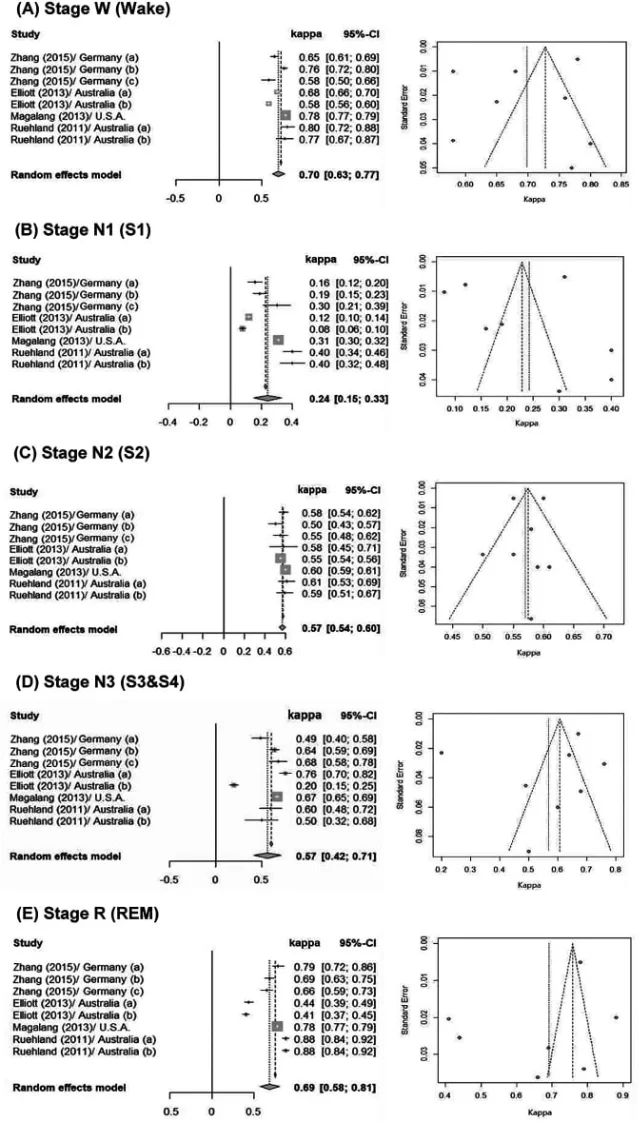
这不是给手环开脱。相反,它把问题推得更深:如果 PSG 的某些边界都带有判读噪声,那么一个没有脑电、只靠外围信号反推的消费级设备,就不该把阶段分钟数呈现得像体温计读数。
正睡症不是「焦虑的人想太多」
Baron 那篇 orthosomnia 病例报告容易被误读成「用户太迷信数据」。这种读法太轻松,也太残忍。病例中的患者并不是随机挑剔。他们带着疲劳、注意力差、烦躁、失眠、睡眠呼吸暂停或不宁腿综合征等真实问题来到诊室。设备没有凭空创造所有痛苦,它给痛苦提供了一个解释框架。
一旦解释框架成形,反证会变得很难进入。B 女士的不宁腿症状经铁补充和加巴喷丁控制后,仍觉得睡眠浅而不恢复;家庭睡眠呼吸暂停测试阴性,实验室 PSG 也显示没有睡眠呼吸暂停,深睡眠比例还偏高。她仍问医生为什么 Fitbit 说她睡得差。1
这类执念有一个行为后果:为了让设备显示更多睡眠,人会延长卧床时间。对失眠者来说,这往往会适得其反。失眠认知行为疗法(CBT-I)经常会限制卧床时间,把床重新训练成睡眠线索。追求更高睡眠时长的设备反馈,可能把人推向相反方向。Baron 等人也承认,病例报告不能证明设备导致了睡眠问题;他们不知道患者是先担心睡眠才开始追踪,还是追踪后才「发现」睡眠问题。1
这个因果谦逊很重要。正睡症不是一个足以把所有责任扔给手表的新诊断。更保守的说法是:当设备分数、睡眠焦虑和错误行为互相强化时,一套反馈回路形成了。
睡眠反馈可以变成安慰剂,也可以变成反安慰剂
睡眠分数还有一个少被讨论的通道:它改变你对今天自己的预期。
Christina Draganich 和 Kristi Erdal 在 2014 年做了两项「placebo sleep」实验。164 名参与者先报告前一晚睡眠质量,然后被随机告知自己的 REM 睡眠占比高于平均水平 28.7%,或低于平均水平 16.2%。被操纵的睡眠质量,而不是自报睡眠质量,显著预测了 Paced Auditory Serial Addition Test 和 Controlled Oral Word Association Task 的表现;对照条件显示,这个结果不能简单归因于实验流程中的需求特征。6
这项研究不等于说「睡眠都是心理暗示」。它说明的是,关于睡眠的反馈本身能进入认知表现。一个设备早上告诉你「恢复不足」,它可能是在报告事实,也可能在给你的一天先扣一分。对自我实验者来说,这很糟糕:你以为自己在测睡眠对表现的影响,结果测进去了「被告知睡得差」对表现的影响。
这个反馈回路解释了为什么一些看似温和的产品设计会有强效应。红色警告、连续天数、恢复分、动物标签、排行榜、目标环,这些元素会把睡眠从身体状态变成可优化任务。优化不是坏事。坏的是用户不知道目标函数是什么,也不知道分数噪声有多大。
更好的用法:看趋势,不审判单夜
睡眠追踪器最适合回答低分辨率问题:我是不是连续几周睡得太少?周末是不是把作息推迟了两个小时?喝酒、晚咖啡、夜间工作、出差后,入睡和起床时间有没有稳定变化?这些问题不要求设备精确知道每段 N3。它只要在同一设备、同一算法、相似佩戴条件下捕捉趋势,就能给出有用线索。
临床指南也更接近这种思路。AASM 指南建议 actigraphy 用于多晚客观评估,独立检测的最小连续记录时长为 72 小时,最长通常可到 14 天;它的价值是把睡眠日志之外的客观模式带进综合评估,而不是取代 PSG 或医生判断。4
把这个原则移到消费级设备上,可以得到一组比较朴素的规则:
- 单夜分数只当提示,不当判决。醒来感觉尚可,却看到低分,不必立刻补救;醒来很疲惫,却看到高分,也不该否定主观体验。
- 总睡眠时间和作息时间比「深睡分钟数」更值得看。后者更依赖设备专有模型,也更容易被用户误读成临床分期。
- 同一设备内看长期趋势,不把不同品牌、不同固件、不同佩戴位置的数值硬比。
- 用睡眠日志保留主观维度:入睡前做了什么,夜里记得醒了几次,白天困不困,情绪和注意力怎样。Baron 等人建议患者不要完全用追踪器代替睡眠日记,正是因为治疗需要同时看到行为和体验。1
- 如果分数开始改变行为,尤其是让人延长卧床、取消活动、反复查看应用、把一天表现归因于昨晚分数,可以做一个更干净的自我实验:连续一两周戴设备但早晨不看分数,先记录主观睡眠和白天功能,周末再统一查看数据。
最后一条尤其适合高控制欲用户。它切断即时反馈,但保留长期观测。这样测到的更可能是睡眠本身,而不是睡眠分数造成的二次反应。
睡眠分数的正确地位
消费级睡眠设备处在一个尴尬位置。它们比纯主观回忆更稳定,比 PSG 更便宜、更可持续,也比医疗级 actigraphy 更容易进入普通生活。与此同时,它们的算法不透明,设备快速迭代,清醒检测和睡眠分期仍有硬伤。用得太少,浪费了一个低负担传感器;用得太重,传感器就变成了夜间道德考官。
最稳妥的地位是「有噪声的行为仪表盘」。仪表盘能提醒偏航,不能替你解释发动机。睡眠分数可以提示作息、压力和恢复之间的关系,但它不该独自决定你是否睡得好、是否需要治疗、今天是不是已经失败。
正睡症的反直觉处在这里:问题往往不是设备不够准,而是设备在局部变准之后,用户更愿意把它扩展到它没有资格回答的问题。一个能较好识别睡眠的传感器,未必能判断睡眠质量;一个能估算长期作息的模型,未必能解释白天疲劳;一个看起来客观的分数,未必比身体的含混感更接近真相。
References
- 1Orthosomnia: Are Some Patients Taking the Quantified Self Too Far?
- 2Performance of seven consumer sleep-tracking devices compared with polysomnography
- 3Wearable Sleep Technology in Clinical and Research Settings
- 4Use of Actigraphy for the Evaluation of Sleep Disorders and Circadian Rhythm Sleep-Wake Disorders
- 5Interrater reliability of sleep stage scoring: a meta-analysis
- 6Placebo sleep affects cognitive functioning
Add more perspectives or context around this Post.